If a file is in use while S3 Sync is trying to upload it, there will be an error. One way to get around this is to use Windows built in functionality of Shadow Copy. This technology creates a read-only point-in-time copy of the volume. S3 Sync can be commanded to upload files from this volume.
Below is a PowerShell script that mounts a drive as a Shadow Copy, creates a symbolic link to that Shadow Copy, runs S3 Sync to upload files, then removes the symbolic link and Shadow Copy volume.
$sourcedrive = "E:\"
echo "sourcedrive=$sourcedrive"
$mountfolder = "E:\shadow copy"
echo "mountfolder=$mountfolder"
echo "Creating the shadow copy"
$shadowid = (Get-WmiObject -List Win32_ShadowCopy).Create("$sourcedrive", "ClientAccessible")
echo "Getting the newly created shadow copy"
$shadowobject = Get-WmiObject Win32_ShadowCopy | Where-Object { $_.ID -eq $shadowid.ShadowID }
$devicepath = $shadowobject.DeviceObject + "\"
echo "Creating symbolic link, calling cmd /c mklink /d $mountfolder $devicepath"
cmd /c mklink /d "$mountfolder" "$devicepath"
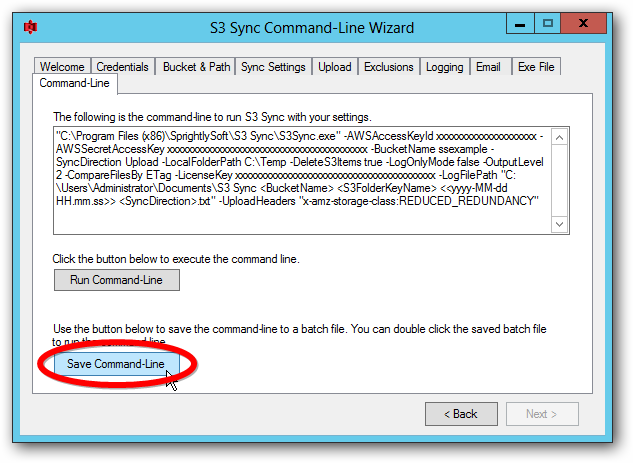
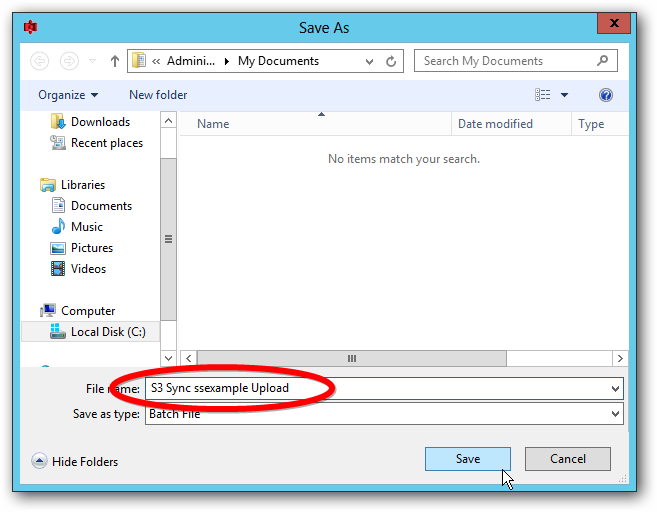
$s3batchfile = "C:\Users\someuser\Documents\Upload with shadow.bat"
echo "Running S3 Sync batch file, calling cmd /c $s3batchfile"
cmd /c $s3batchfile
echo "Removing the symbolic link, calling cmd /c rmdir $mountfolder"
cmd /c rmdir "$mountfolder"
echo "Deleting the shadow copy"
$shadowobject.Delete()
To use this script put the code in a file with the .ps1 extension. For example the name can be ShadowCopyUpload.ps1.
Modify the $sourcedrive and $mountfolder values to match the drive letter where you will be uploading files from.
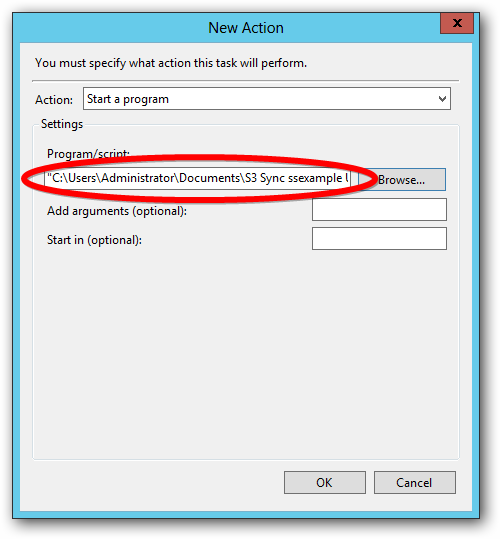
Modify the $s3batchfile value with a path to an S3 Sync batch file. This batch file should contain the command S3 Sync will use to upload from the mount folder.
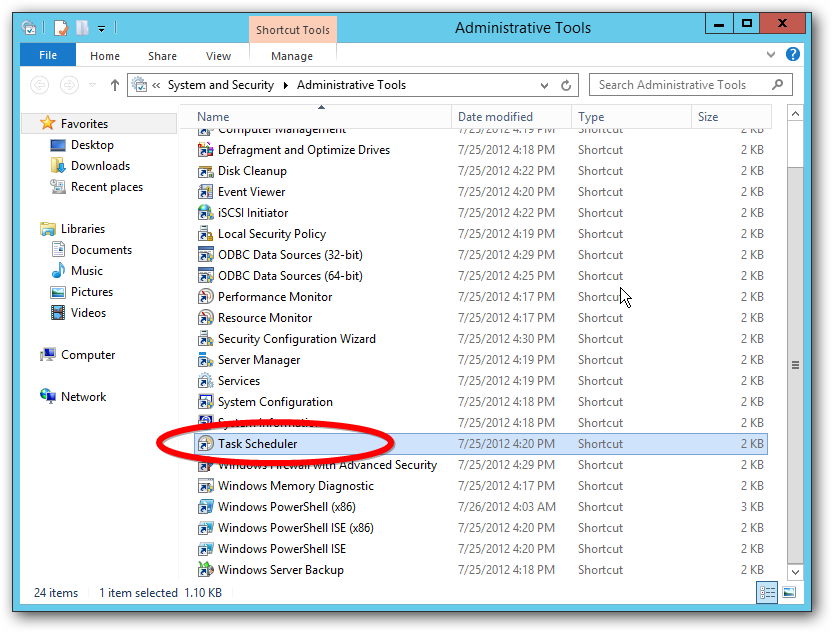
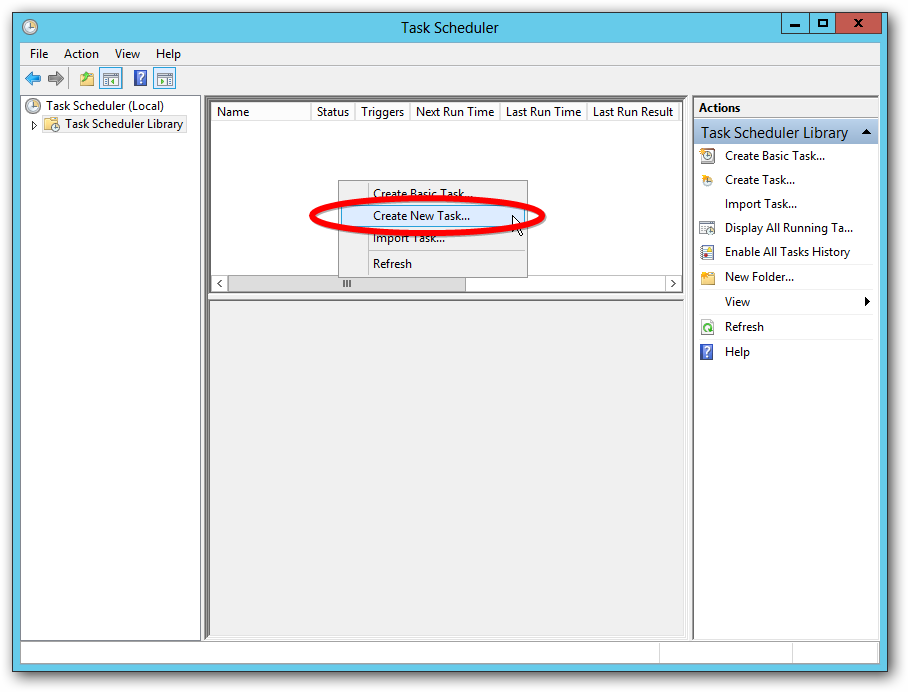
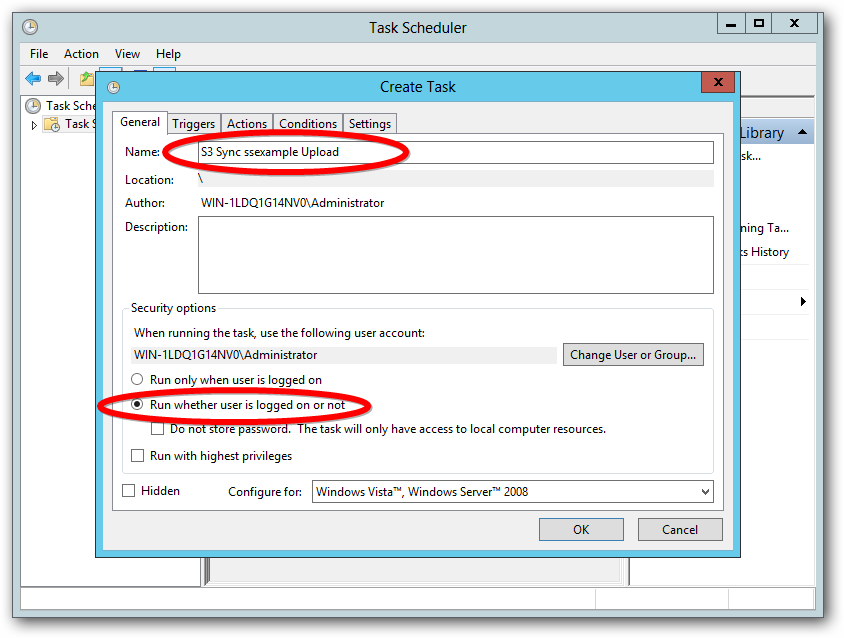
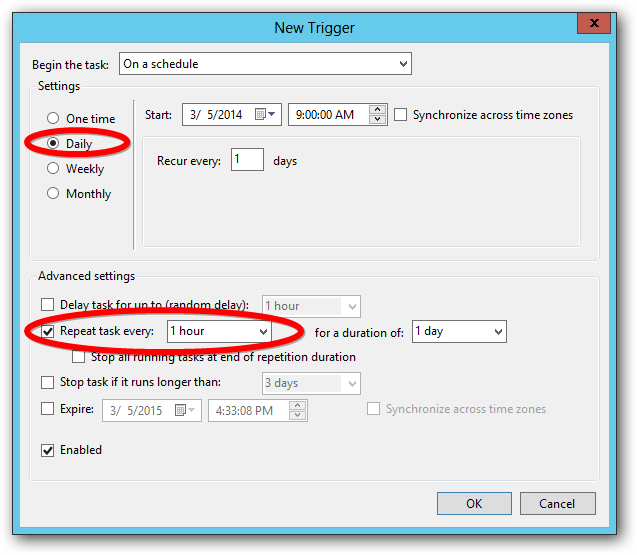
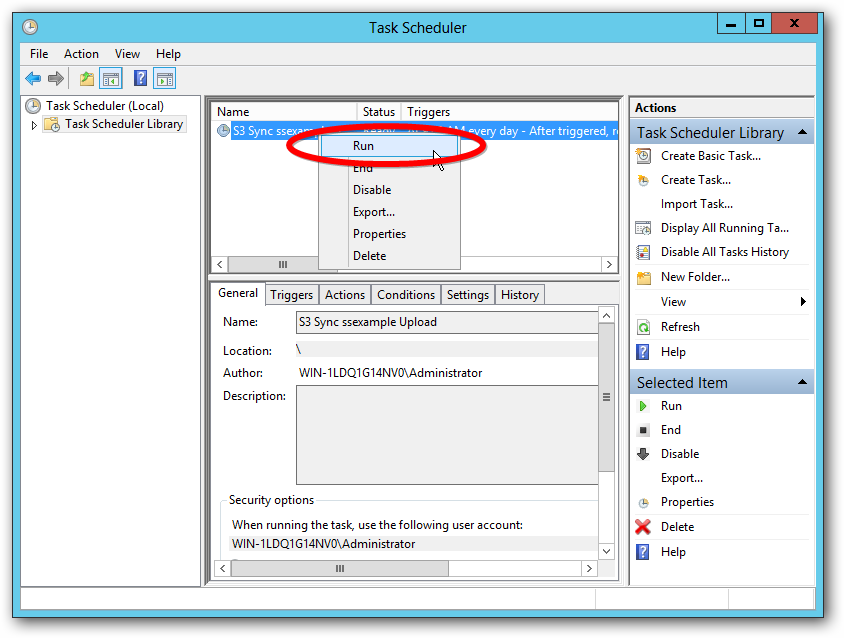
If the PowerShell script is run as a Scheduled Task, the task needs to be set with “Run with highest privileges”.
If you run the PowerShell script from the PowerShell command prompt, run the prompt as an administrator.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}